


YOLOv9 vs. YOLOv8: Leistungsbewertung
Recent Post:

YOLOv9 vs. YOLOv8: Beurteilung der Leistung
Was ist YOLO?
Bevor wir uns dem Vergleich widmen, wollen wir kurz zusammenfassen, worum es bei YOLO geht. You Only Look Once (YOLO) ist eine Architektur zur einstufigen Objekterkennung, die Bounding Boxes und Klassenwahrscheinlichkeiten direkt aus einem Eingabebild vorhersagt. Dieser Ansatz unterscheidet sich von früheren Objekterkennungsalgorithmen, die Klassifikatoren zur Erkennung verwenden. Es verarbeitet das gesamte Bild in einem Durchgang, was es für Echtzeitanwendungen ausgesprochen effizient macht.

Fig 1: YOLO Pipeline
Seit der ersten Veröffentlichung von YOLO im Jahr 2015 wurden mehrere neue Versionen desselben Modells vorgeschlagen.
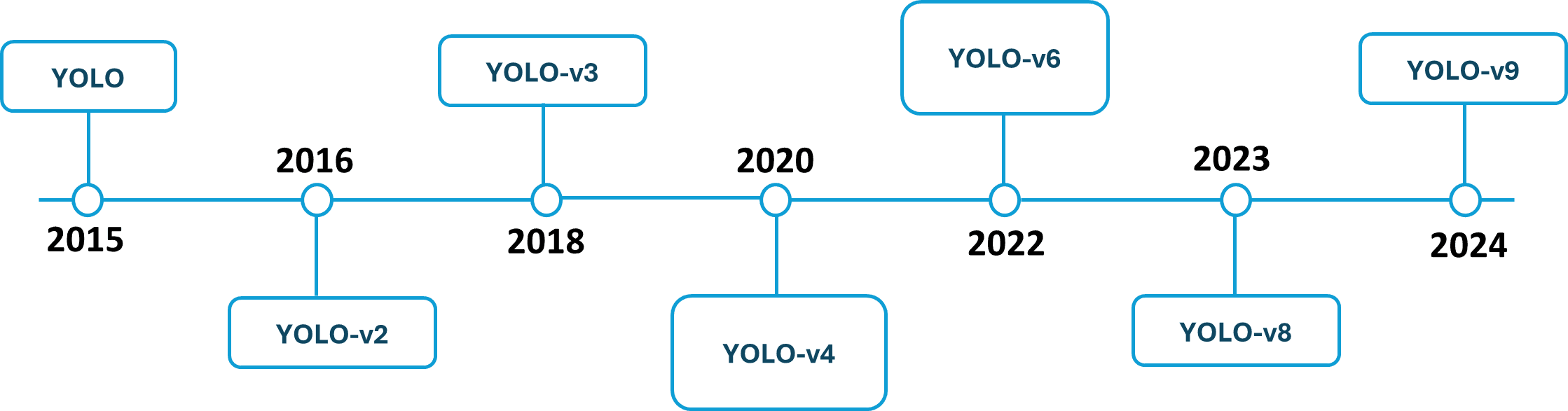
Fig 2: YOLO Zeitachse
YOLOv8
YOLOv8 wurde 2022 von Ultralytics auf den Markt gebracht. YOLOv8 baut auf dem YOLOv5-Framework auf und enthält mehrere Verbesserungen der Architektur und der Entwicklererfahrung. YOLOv8 wurde aufgrund seiner Ausgewogenheit zwischen Geschwindigkeit und Genauigkeit populär. Es bietet eine schnellere Inferenz und behält die Echtzeitleistung bei, wodurch es für Anwendungen geeignet ist, die eine geringe Latenz erfordern. YOLOv8 erkennt einen höheren Anteil echter positiver Ergebnisse bei gleichzeitiger Minimierung der Fehlalarme. Seine Präzisions-Rückruf-Kurve zeigt seine Überlegenheit sowohl in der Präzision als auch im Rückruf. YOLOv8 erlaubt die Feinabstimmung auf benutzerdefinierte Datensätze. Benutzer können YOLOv8 auf spezifische Objektklassen trainieren, die für ihre Anwendung relevant sind.
Segmentierung
YOLOv8 überrascht mit seiner Fähigkeit, Instanzen zu segmentieren. Während YOLOv9 sich hauptsächlich auf die Objekterkennung konzentriert, kann YOLOv8 Objekte auch auf Pixelebene segmentieren. Diese Funktion ist für Aufgaben wie semantische Segmentierung und medizinische Bildgebung von unschätzbarem Wert.
Pose Estimation
Die oft vernachlässigte Pose-Schätzung ist ein wichtiger Aspekt des maschinellen Sehens. YOLOv8 kann die Orientierung oder Pose von erkannten Objekten schätzen. Es können damit Yoga-Posen verfolgt werden, Sportbewegungen analysiert werden oder Augmented-Reality-Anwendungen verbessert werden.
YOLO-Welt
Das Modell YOLO-World stellt eine hochmoderne Echtzeitmethode für Aufgaben zur Erkennung von offenem Vokabular vor. Dies ermöglicht die Identifikation von Objekten in Bildern anhand von beschreibenden Texten. YOLO-World zeichnet sich als vielseitiges Werkzeug für verschiedene bildverarbeitungsbasierte.
Anwendungen aus, da es den Rechenaufwand bei konkurrenzfähige Leistung erheblich reduziert.
YOLOv9
YOLOv9 baut auf dem Erbe der Vorgängerversionen auf und führt architektonische Verbesserungen ein. Das ist der Unterschied: YOLOv9 enthält Weiterentwicklungen wie Programmable Gradient Information (PGI) und das Generalized Efficient Layer Aggregation Network (GELAN). PGI verhindert Datenverluste bei Gradientenaktualisierungen, während GELAN leichtgewichtige Modelle durch Gradientenpfadplanung optimiert. Durch die Integration von PGI und der anpassungsfähigen GELAN-Architektur erhöht YOLOv9 nicht nur die Lernfähigkeit des Modells, sondern stellt auch sicher, dass wichtige Informationen während des gesamten Erkennungsprozesses erhalten bleiben. Der Fortschritt von YOLOv9 konzentriert sich im Wesentlichen auf die Lösung der Probleme, die durch den Informationsverlust in tiefen neuronalen Netzen entstehen. Sein Design berücksichtigt das Prinzip des Informationsengpasses und verwendet auf innovative Weise reversible Funktionen, um sicherzustellen, dass YOLOv9 sowohl hohe Effizienz als auch hohe Genauigkeit beibehält.
GELAN(Generalized Efficient Layer Aggregation Network)
YOLOv9 behält den Ruf der YOLO-Familie für schnelle Verarbeitung mit einer neuen Struktur namens GELAN bei, die die besten Elemente von CSPNet und ELAN kombiniert. CSPNet eignet sich hervorragend für die Verwaltung des Datenflusses, um wichtige Funktionen effizient zu extrahieren, während ELAN sich auf die schnelle Verarbeitung mit überlagerten Schichten konzentriert. GELAN kombiniert diese Eigenschaften und bietet ein Design, das nicht nur leicht und schnell, sondern auch genau ist. Es verbessert ELAN, indem es nicht nur Schichten, sondern auch verschiedene Arten von Verarbeitungsblöcken stapelt, was die Geschwindigkeit und Effizienz des Modells in allen seinen Teilen erhöht.
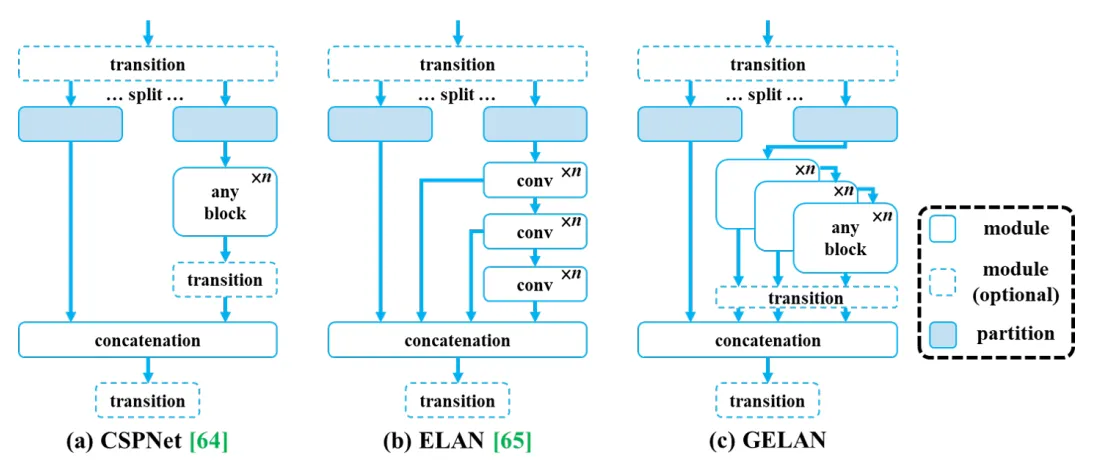
Fig 3. Gelan Architecture
PGI (Programmable Gradient Information)
YOLOv9 befasst sich mit einem häufigen Problem beim Deep Learning, dem sogenannten „Informationsengpass“. Dies ist der Fall, wenn wichtige Details verloren gehen, während sich die Daten durch die vielen Schichten eines neuronalen Netzes bewegen, was zu Fehlern in dem führen kann, was das Netz lernt oder vorhersagt. Um dieses Problem zu lösen, führt YOLOv9 ein intelligentes Werkzeug namens Programmable Gradient Information (PGI) ein.
Stellen Sie sich das neuronale Netz als ein langes Rohr vor, durch das Informationen fließen. Manchmal können wichtige Details durch Ritzen rutschen. PGI ist wie ein spezieller Pfad in diesem Rohr, der sicherstellt, dass die wirklich wichtigen Informationen nicht verloren gehen. Zu diesem Zweck wird neben dem Hauptpfad ein Nebenpfad - eine Art Gedächtnispfad - angelegt. Dieser Nebenpfad hilft dem Netz, sich an wichtige Details zu erinnern und sie zu nutzen, wodurch es besser lernen und genauere Vorhersagen über das Gesehene treffen kann, z.B. die Identifizierung von Objekten auf einem Foto.
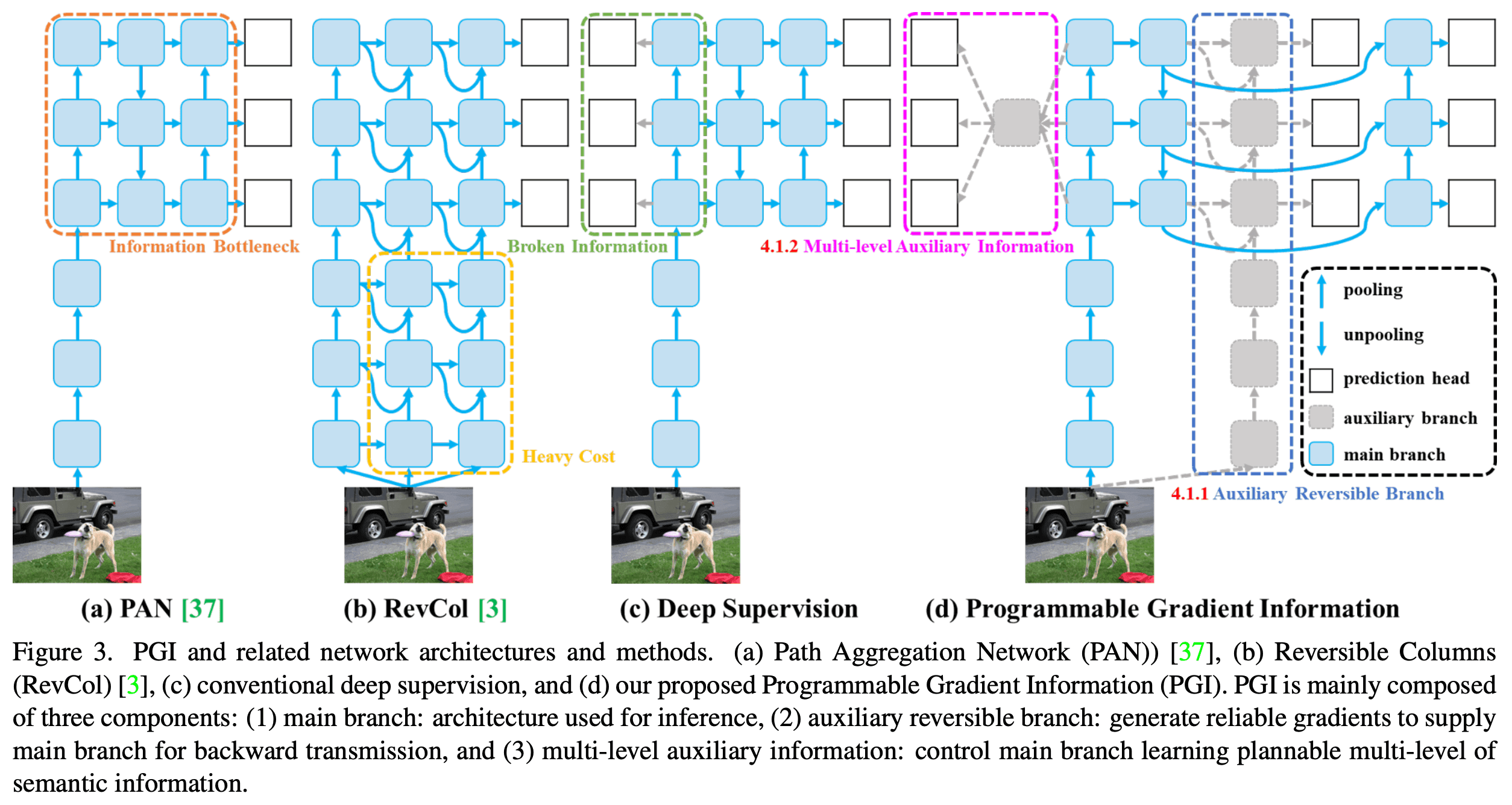
Fig 4. PGI Architecture
Vergleichende Analyse
Die Leistung von YOLOv9 auf dem COCO-Datensatz zeigt die Fortschritte in der Objekterkennung und bietet eine harmonische Mischung aus Effizienz und Genauigkeit in den verschiedenen Versionen. Mit verbesserter Genauigkeit und reduziertem Rechenaufwand setzt YOLOv9 die Standards früherer Versionen der YOLO-Reihe fort.
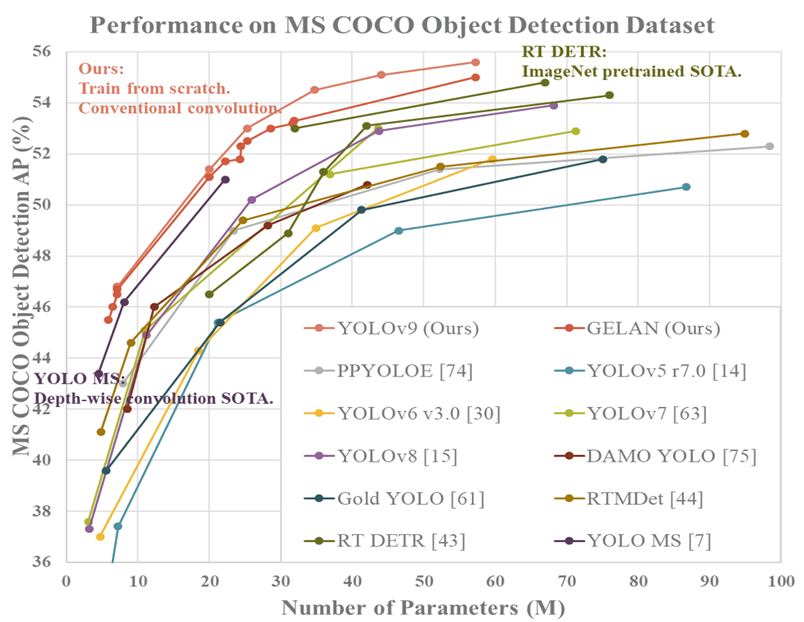
Fig 5. YOLOv9 performance on coco datasets
YOLOv9 übertrifft YOLOv8 in der Genauigkeit. Das Modell YOLOv9e setzt einen neuen Standard für große Modelle mit 15% weniger Parametern und 25% weniger Rechenaufwand als YOLOv8x. Mit einer weiteren Verbesserung der AP um 1,7%.
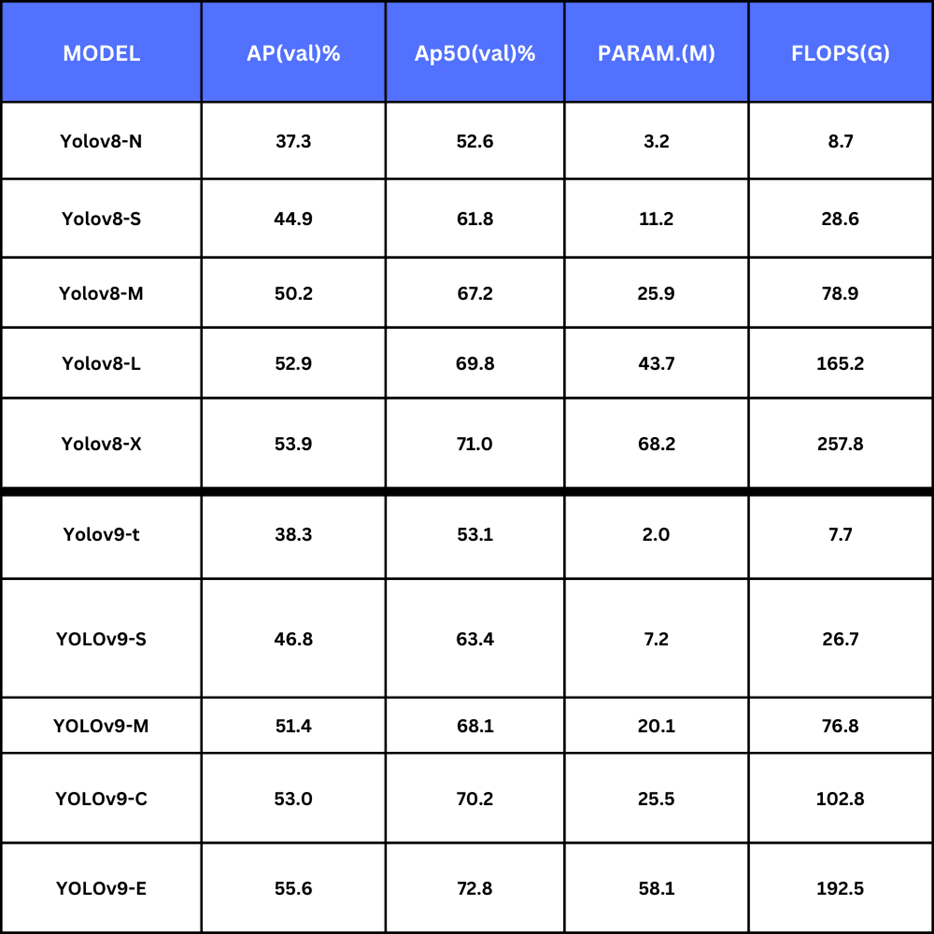
Yolov9: Die wichtigsten Ergebnisse
Die YOLO-Modelle haben sich aufgrund ihrer außergewöhnlichen Leistungsfähigkeit und Vielseitigkeit zum Maßstab für die Objekterkennung entwickelt. Hier sind unsere ersten Erkenntnisse über YOLOv9:
· YOLOv9: Benutzerfreundlichkeit: YOLOv9 ist auf GitHub verfügbar und kann schnell über die Kommandozeilenschnittstelle (CLI) oder die integrierte Entwicklungsumgebung (IDE) in Python implementiert werden.
· YOLOv9 Aufgaben: YOLOv9 demonstriert Effizienz bei der Objekterkennung in Echtzeit und bietet verbesserte Genauigkeit und Geschwindigkeit.
· YOLOv9 Verbesserungen: Zu den wichtigsten Verbesserungen von YOLOv9 gehören ein entkoppelter Kopf mit ankerfreier Erkennung und eine Mosaikdaten-Erweiterung, die sich nach den letzten zehn Trainingsepisoden abschaltet.
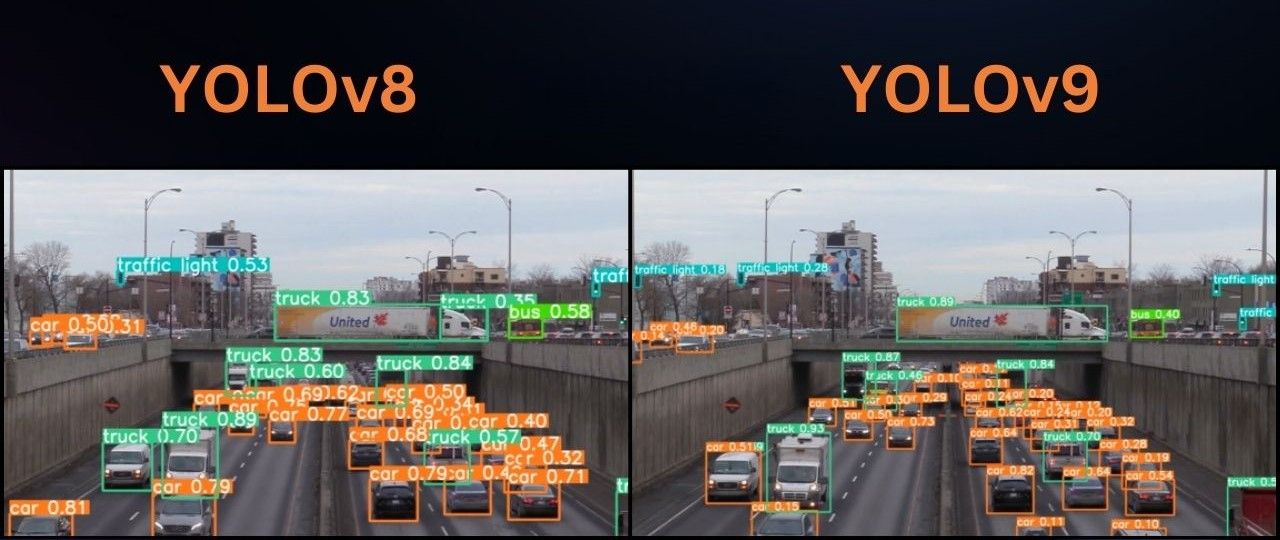
Die durchgeführten Experimente zeigen, dass das Modell YOLOv9 bei der Erkennung kleinerer und weiter von der Kamera entfernter Objekte besser abschneidet als YOLOv8, wie das bekannte Video mit der Ampelerkennung zeigt. Umgekehrt zeigt YOLOv8 seine Überlegenheit bei der Erkennung von Objekten im Nahbereich und bei der Behandlung von Fehlerkennungen. Interessanterweise zeigt YOLOv8 trotz der größeren Anzahl an Parametern eine deutlich schnellere Performance als die PyTorch-Modelle, die sofort einsatzbereit sind. Weitere Tests mit Frameworks wie ONNX/TensorRT sind jedoch gerechtfertigt, um die Leistung vollständig beurteilen zu können.
Literaturhinweis
Chien-Yao Wang, I-Hau Yeh. „Liaohttps://arxiv.org/pdf/2402.13616.pdf“(2024)
Joseph Redmon, Ali Farhadi. „https://arxiv.org/abs/1506.02640“
Die YOLO-Modelle haben sich aufgrund ihrer außergewöhnlichen Leistungsfähigkeit und Vielseitigkeit zum Maßstab für die Objekterkennung entwickelt. Hier sind unsere ersten Erkenntnisse über YOLOv9:
· YOLOv9: Benutzerfreundlichkeit: YOLOv9 ist auf GitHub verfügbar und kann schnell über die Kommandozeilenschnittstelle (CLI) oder die integrierte Entwicklungsumgebung (IDE) in Python implementiert werden.
· YOLOv9 Aufgaben: YOLOv9 demonstriert Effizienz bei der Objekterkennung in Echtzeit und bietet verbesserte Genauigkeit und Geschwindigkeit.
· YOLOv9 Verbesserungen: Zu den wichtigsten Verbesserungen von YOLOv9 gehören ein entkoppelter Kopf mit ankerfreier Erkennung und eine Mosaikdaten-Erweiterung, die sich nach den letzten zehn Trainingsepisoden abschaltet.
Die durchgeführten Experimente zeigen, dass das Modell YOLOv9 bei der Erkennung kleinerer und weiter von der Kamera entfernter Objekte besser abschneidet als YOLOv8, wie das bekannte Video mit der Ampelerkennung zeigt. Umgekehrt zeigt YOLOv8 seine Überlegenheit bei der Erkennung von Objekten im Nahbereich und bei der Behandlung von Fehlerkennungen. Interessanterweise zeigt YOLOv8 trotz der größeren Anzahl an Parametern eine deutlich schnellere Performance als die PyTorch-Modelle, die sofort einsatzbereit sind. Weitere Tests mit Frameworks wie ONNX/TensorRT sind jedoch gerechtfertigt, um die Leistung vollständig beurteilen zu können.
Literaturhinweis
Chien-Yao Wang, I-Hau Yeh. „Liaohttps://arxiv.org/pdf/2402.13616.pdf“(2024)
Joseph Redmon, Ali Farhadi. „https://arxiv.org/abs/1506.02640“
Comment
0Comments
No comments yet.
