


Synthetic Data Generation With Computer Vision
Recent Post:


The creation of synthetic visual data has greatly impacted the world of computer vision, creating a solution to issues surrounding limited data, ethical concerns, and costs in collecting real-world data. Essentially, synthetic data is information that did not originate in the real world but rather came from computer algorithms or simulations. In this way, this information substitutes for real data during the training of machine learning models. In computer vision, this form of data often includes computer-generated images and videos depicting real-life events and circumstances. However, this type of data is particularly useful to individuals when a specific kind of data is hard to obtain and expensive, or when it involves a breach of highly confidential Personal Identifiable Information (PII).
The approach has also witnessed adoption in other industries such as healthcare, and agriculture among other areas where the approach offers custom-designed, high-quality training datasets without the logistical and ethical challenges accompanying conventional data gathering. From child catheters to autonomous driving, synthetic data generation is taking computer vision to new heights, with new possibilities emerging every day. Here, we’ll explore synthetic data in-depth: its types, its generation techniques and tools, and how best to utilize synthesized data to assist in solving complex data challenges.
Synthetic data generation
What is Synthetic Data?
Synthetic data refers to information that can be considered as real but has not originated from any real-life event. Such data can be produced by employing methods that include but are not limited to VAE, GAN, etc. Generative data is often used for testing, verifying other datasets, and deep learning systems. It aids in mimicking infrequent events or events that are not likely to occur together and can also be created to suit particular needs, especially when real data is hard to obtain or is too sensitive or expensive to create. Similarly, synthetic datasets can also be used for software testing and AI model training.
Importance of Synthetic Data:
Synthetic data is considered useful for two reasons.
1. It addresses important issues faced by standard datasets such as, “how to collect datasets in expensive or rare situations” and “how to collect and store such datasets considering privacy issues”.
2. It gives dataset creators the ability to specify certain parameters, which allows such datasets to not be sensitive or use too much time. For example, in the field of AI technologies, such scenarios would allow an organization to tackle the challenges of providing sensitive information while also reducing the considerable logistical challenges of training AI.
Additionally, in medicine, there is synthetic data that emulates real medical data without compromising the privacy of patients, uniformly retaining critical statistical parameters, and thus can be useful for parameterizing AI systems. While it is a very effective tool in combat, it still has limitations, such as the risk of not accurately reproducing the complexities of the real world, and that is why in some situations, high-quality data will always remain relevant.
The Role of Synthetic Data in Advancing Computer Vision
The generation of synthetic data has proven to be successful in enhancing the performance of AI models in terms of accuracy, robustness, and scalability since it is a deriving point for models. In contrast to the old techniques where temporal labor-intensive and inaccurate manual data labeling was the only available option, this alternative technique deploys advanced methods such as GANs, VAEs, physics-based rendering engines like Unreal Engine and Unity as well as geometry-aware neural rendering. These tools can provide images and 3D scenes as per the requirements in very minute detail, and this makes it possible to build models that can be trained on multiple datasets that are as close to reality as possible.
This paradigm shift assists in alleviating major bottlenecks in computer vision with regards to sourcing unlabelled data as well as the use of real-life data which raises stability issues. The use of synthetic data allows the formation of edge cases as well as rare edge cases and scenarios that will be of great use when trying to build aspects such as self-driving cars or biometrics. This also serves as a solution that is cost-effective, scalable and has minimal to no privacy concerns while also being able to generate labeled data.
Nonetheless, synthetic data has some drawbacks as well. The performance of the model can be impacted if there are differences between the synthetic and the real-world data, which leads to the need for techniques such as transfer learning and domain adaptation. Even so, synthetic data is finding its way into redefining computer vision use cases and laying the groundwork for AI systems that are more flexible in terms of performance in a variety of real-world challenges.
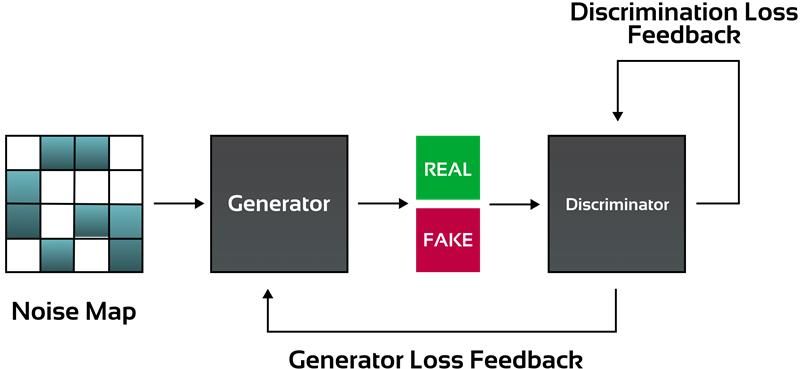
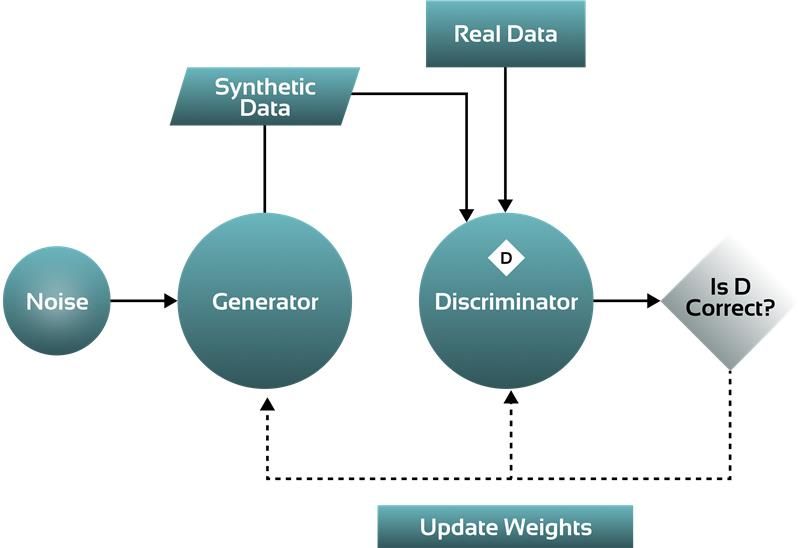
Training algorithm of Generative Adversarial Network (GAN) for creating synthetic data.
Synthetic Data in Computer Vision: Techniques and Methods
With the ability to scale and reduce costs, synthetic data generation has emerged as one of the most important technologies needed to develop artificial intelligence models, particularly computer vision models. As part of this, we focus on the main techniques and tools that aim to improve synthetic data generation.
1. Domain Adaptation
The domain adaptation feature is essential for AI models that require temperature changes during deployment. In NVIDIA's Omniverse Replicator, because alterations are structured, robots battling omniverse adaptation face minimal recruitment costs, which makes it paramount in robotics and autonomous vehicles.
2. Transfer Learning
Transfer learning reduces the amount of real-world data and focuses on fine-tuning models after training them on synthetic datasets. It is very pragmatic in situations where real-world data is either very limited or very expensive to obtain. This is the case with relying on Trimble’s method for training Boston Dynamics’ construction Spot robot.
3. Hybrid Data Strategies
A hybrid model that includes both synthetic data and real-world data tends to perform better and generalize better than a model consisting of either one of the two. Hybrid methods, of which SURREAL is integrated in conjunction with real-world data, tend to outperform methods that rely solely on real-world data sources.
4. Generation Using Simulators
Simulation tools such as the Isaac Sim by NVIDIA create artificial spaces that are representative of real-world environments. These simulated environments are suitable for training AI models for robotics, autonomous vehicles, and industrial tasks, achieving accelerated, flexible, and affordable data generation.
5. Analysed Methods of Statistical Distribution
This technique creates additional datasets by considering and mimicking the statistical features of data, such as mean, variance, distribution type, etc. Though it is quick in practice, it is often unable to grasp intricate patterns and thus depends greatly on the expertise of specialized data scientists for correct and plausible representation.
6. Individual Agents Models
As an abstraction paradigm in which the real world is represented in the form of a collection of autonomous interacting entities, each one referred to as an agent that behaves according to a set of rules, systems are simulated using algorithms like iterative proportional fitting (IPF) and combinatorial optimization. It is usually applied in economics, healthcare, and system analysis.
7. IA Generative Models
Generative Adversarial Networks (GANs) and Variational Auto Encoders (VAEs) are new generative techniques for synthetic data:
GANs: Employ a generator called a discriminator which, through competition, outputs realistic data sets.
VAEs: Use an encoder-decoder put together to produce different data sets, thereby representing real-world scenarios.
8. Domain Randomization and Synthetic Refinement
The controlled randomness added by domain randomization to synthetic sets aids in achieving the goal of replicating real-world variability. Moreover, NVIDIA's Isaac Replicator and self-regularisation, for instance, enhance the datasets which improve performance in real life as well.
9. Iterative Improvement
Iterative tuning of the parameters of the synthetic dataset optimizes it in such a way that the results of the training are better. To illustrate, a door detection model’s average precision (AP) was able to go from 5% to 87% after applying iterative changes.
Applications & Use Cases of Synthetic Data
Gaps in data availability and quality can be bridged by synthetic data which can help make innovation, data scaling, and advancement of AI and ML models a possibility across multiple sectors. Below we outline its applications and benefits:
1. Inclusion of More Diverse & Relevant Data For Training AI Algorithms:
AI algorithms such as Deep Learning models require data representation to allow the algorithm to learn. Synthetic data allows models to be trained on data that is more diverse allowing their accuracy to be improved.
Example: Images or videos of vehicles can be scanned for specific information such as their size or color by AI algorithms with artificial images as they can see a wide variety of lighting conditions.
2. Generation of Specific Tailor-Made Datasets Synthetic Data Uses
This form of data is effective for those editors and trained individuals who wish to create custom-tailored data for specific requirements when the real-world data available is very hard to come by or sensitive.
Example: Specific custom-made synthetic images can be used by physicians for analysis without having to go through any strict privacy policies which can make it a tedious task to find valid patient data.
3. Improving Existing Models With The Help Of Synthetic Data
Models that use facial recognition based on most learning algorithms are usually plagued with clusters. Synthetic Data can be used to solve this issue as it effectively blurs the data cluster when combined with real data of the same type.
Example: Multi-ethnic positioned images of faces can be compensated with random artificially made generic faces which eliminate the clustering issue along with racism.
4. Closing Down the Lacunae in Production with Data
For critical scenarios, where real-world data is lacking or missing, synthetic data comes in handy and assists well in the context of high-risk situations.
For instance: Autonomous driving vehicles run simulations with synthetic datasets under rare circumstances for the vehicle, like harsh weather, without venturing outside.
5. Better Equivalence, Lesser Biases
AI models can get rid of disparate bias through lower-level demographic exposure with the help of synthetic data.
For example: The synthetic balance assures diversity in the datasets for face recognition systems, hence curvature and patterns of anti-discriminatory practices.
6. Advanced AI Within a Short Time
Creating synthetic data is easier and cheaper than going out in the field to collect data hence AI progresses faster.
For instance: A risk scenario is created for Fraud detection systems to quickly adjust and test detection algorithms with ease.
7. Applying Strong Ethics About Data Privacy and Security
While avoiding sensitive data, synthetic data serves its purpose by mimicking real-life data formats successfully.
For everyone concerned: Synthetic personal data is used instead of physical identities to enable compliance with GDPR and similar regulations facilitating safe innovations and data exchange.
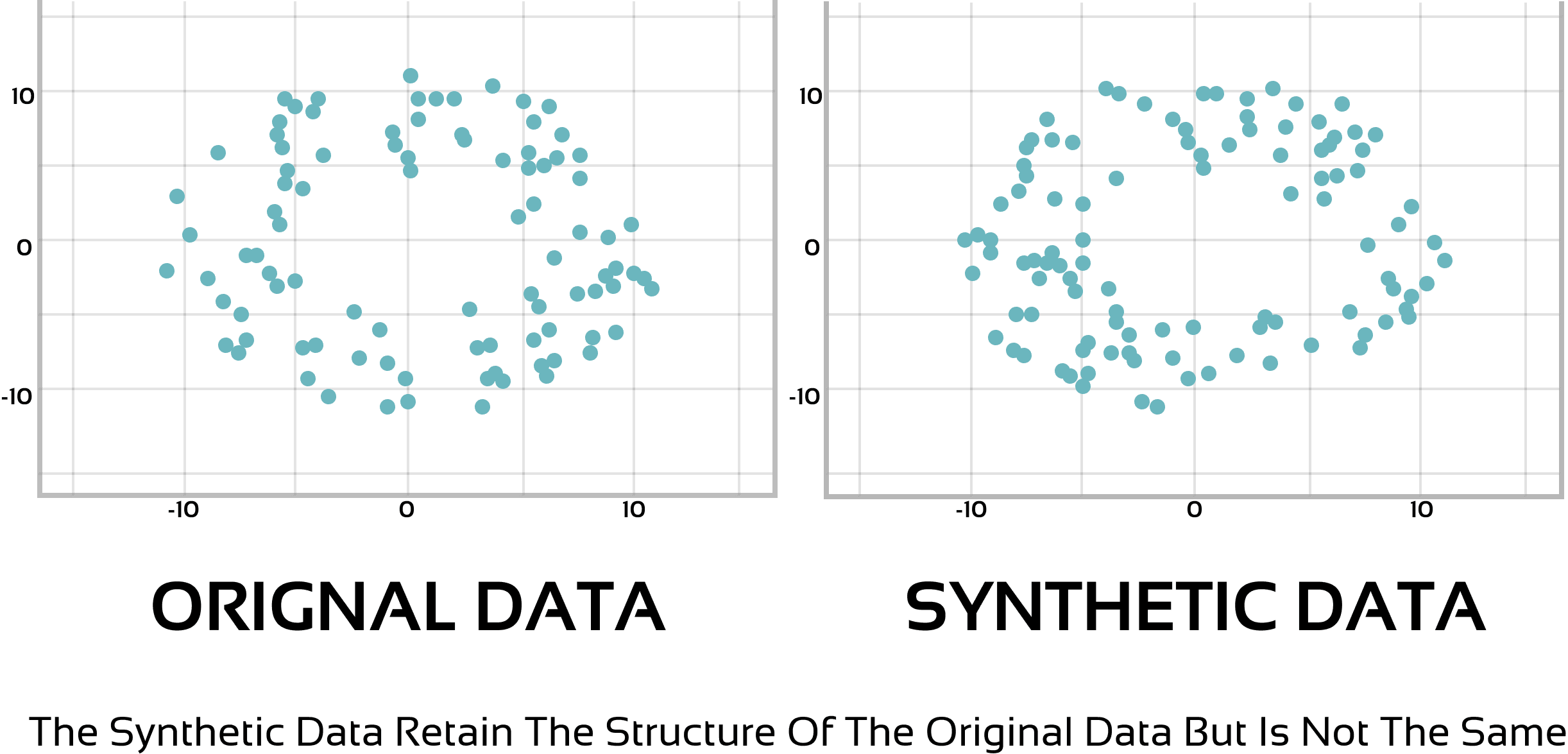
The difference in structure between authentic and synthetic data promotes data privacy and security.
Industry-Specific Implementation Strategies
Healthcare
Learn AI algorithms for medical imaging while avoiding breaching patient confidentiality.
Forecast diseases and guess movements using synthetic epidemiological data.
Agriculture
To allow for crop yield predictions, disease outbreak detection, and tracking plant growth, computer vision is implemented.
Banking and Finance
Carry out advanced fraud through simulations of synthetic data and replicas.
E-commerce
Enhance warehousing, inventory management, and online customer service using synthetic datasets.
Manufacturing Industry
Implement the use of synthetic data for predictive maintenance and quality control.
Disaster Forecasting and Risk Management
Harness simulated data to predict natural calamities and reduce disaster risks.
Automotive and Robotics
Create autonomous vehicles, drones, and robots using synthetic data to interact with varied and complex environments.
Best Practices for Synthetic Data Integration
In this way you will make the most out of synthetic data:
Combine Synthetic Data with Real Data: Make the models work using strong hybrid datasets.
Iterate your Dataset Generation: Enhance the performance of models by frequent enhancement of synthetic data.
Maintain Ethics: Create synthetic data with bias-free data to encourage fair practices.
Check the Model Functioning: Routinely perform operability tests for models on live datasets for effectiveness.
Challenges and Limitations in Implementing Synthetic Data
Data Quality Limitations: Synthetic data may not always accurately reflect the real world, leading to underperforming models. Additionally, techniques like noise injection can introduce biases or artifacts that negatively affect model accuracy.
Privacy Concerns: Generating synthetic data from sensitive real-world data could risk privacy breaches, especially if the data is not properly anonymized. In some cases, it may be susceptible to reverse engineering.
Technical and Practical Challenges: Creating high-quality synthetic data can be costly and time-consuming, particularly for complex datasets. Additionally, generation methods may not be applicable for all data types or use cases, depending on the domain and available resources.
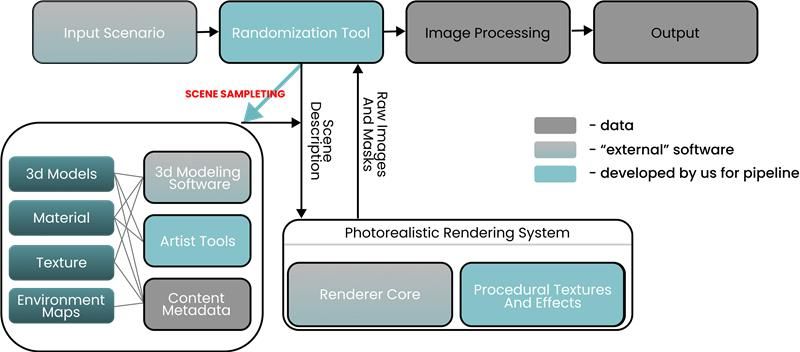
The proposed architecture of a synthetic data generation system.
The Future Outlook of Synthetic Data
The adoption of synthetic data is expanding across various industries, and its impact on the areas of data privacy, AI advancements, and moral values has become quite evident. Take a look at the features of synthetic data which will set a course for the coming times.
1. Ability to Change Perceptions Regarding Data Privacy
Privacy risks are the main challenges preventing the sharing of personal data. Enhancement of personal data protection and substitution of identity-sensitive elements with artificial-content-driven equivalents pave the way for data collaboration, innovation, and ethicality of AI. This capability makes synthetic data a powerful tool, especially with the existence of laws regarding data privacy like the GDPR law Ready certification EUDPR. It seeks to change the current data control and sharing practices of organizations in light of assistance with policy compliance.
2. Creating Opportunities for Synthesising Innovation in AI
It is projected that researchers will be able to discover AI technologies and their applications in real-world situations much faster; accessible artificial data will help eliminate interference caused by the serious lack of accessibility of real data. Researchers will be able to launch experiments, test ideas, and perfect new concepts without worrying about the cost of employing people to gather the information. Open access to data will spark creativity and even increase the pace of AI technology inventions.
3. Combating Ethical Issues and Implementing Responsible AI
It is essential to set some principles for the ethical generation and use of synthetic data. This addresses concerns relating to abuse, transparency, fairness, bias, etc. Responsible AI practices will ensure that the synthetic data generated is used to target the building of fair, non-discriminatory, and trustworthy AI models, reducing betrayals and confidence in AI systems.
Conclusion:
The future of synthetic data in computer vision looks promising, offering a transformative solution to challenges like data scarcity, high costs, and ethical concerns around real-world data collection. By generating data through algorithms or simulations, synthetic data enables AI models to be trained effectively without relying on difficult-to-obtain or sensitive real-world data.
Industries such as healthcare, agriculture, autonomous driving, and robotics are already benefiting from synthetic data, which allows for the creation of custom datasets tailored to specific needs. It also enhances AI model performance by providing diverse, high-quality data, reducing the costs and logistical complexities of real-world data collection.
However, challenges remain, including the need for synthetic data to closely mirror real-world scenarios to ensure accurate model performance, along with concerns over privacy, biases, and inaccuracies. With advancements in generative models, domain adaptation, and hybrid data strategies, synthetic data is becoming a key enabler of robust, scalable, and ethical AI systems.
Looking ahead, synthetic data is poised to accelerate AI innovation, developing greater accessibility, inclusivity, and transparency in AI applications while reducing reliance on sensitive personal data. As technology evolves, synthetic data is set to play a pivotal role in reshaping the future of AI and computer vision.
Comment
0Comments
No comments yet.
